
Manipulando a ordem de resolução de campos
O objetivo da diretiva @export fornecida por Multiple Query Execution é exportar o valor de um campo (ou conjunto de campos) para uma variável, a ser utilizada em outro lugar na query.
Esta diretiva não funcionaria se a leitura da variável ocorresse antes da exportação do valor para a variável. Portanto, o motor precisa fornecer uma maneira de controlar a ordem de execução dos campos.
O Gato GraphQL oferece uma maneira de manipular a ordem de execução dos campos por meio da própria query. O motor carrega os dados em iterações para cada tipo, resolvendo primeiro todos os campos do primeiro tipo que encontra na query, depois todos os campos do segundo tipo que encontra na query, e assim por diante até que não haja mais tipos a processar.
Por exemplo, a seguinte query envolvendo objetos dos tipos Director, Film e Actor:
{
directors {
name
films {
title
actors {
name
}
}
}
}...é resolvida pelo motor GraphQL nesta ordem:

Se, após ser processado, um tipo for referenciado novamente na query para recuperar dados não carregados (por exemplo: de objetos adicionais, ou campos adicionais de objetos já carregados), então o tipo é adicionado novamente ao final da lista de iteração.
Por exemplo, se também consultarmos o campo preferredDirector do Actor (que retorna um objeto do tipo Director) desta forma:
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}...então o motor GraphQL processa a query nesta ordem:

Vamos ver como isso se desenrola para executar @export em uma única query. Na nossa primeira tentativa, criamos a query como faríamos normalmente, sem pensar na ordem de execução dos campos:
query GetPostsAuthorNames {
user(by: { id: 1 }) {
name @export(as: "authorName")
}
posts(filter: { search: $authorName }) {
id
title
}
}Ao executar a query, ela produz esta resposta:
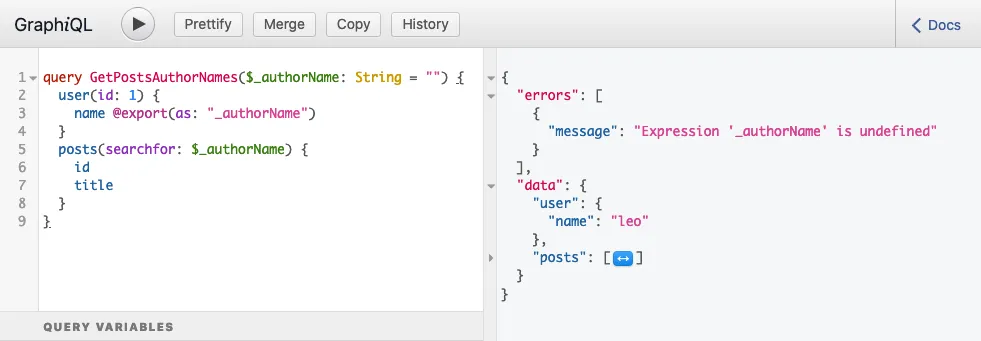
...que contém o seguinte erro:
{
"errors": [
{
"message": "Expression 'authorName' is undefined",
}
]
}Este erro significa que, no momento em que a variável $authorName foi lida, ela ainda não havia sido definida; estava undefined.
Vamos entender por que isso acontece. Primeiro, analisamos quais tipos aparecem na query, adicionados como comentários abaixo:
# Type: Root
query GetPostsAuthorNames {
# Type: User
user(by: {id: 1}) {
# Type: String
name @export(as: "authorName")
}
# Type: Post
posts(filter: { search: $authorName }) {
# Type: ID
id
# Type: String
title
}
}Para processar os tipos e carregar seus dados, o motor de carregamento de dados adiciona o tipo da query Root em uma lista FIFO (First-In, First-Out, "primeiro a entrar, primeiro a sair"), tornando [Root] a lista inicial passada ao algoritmo, e então itera sobre os tipos sequencialmente, desta forma:
| # | Operação | Lista |
|---|---|---|
| 0 | Preparar a lista FIFO | [Root] |
| 1a | Remover o primeiro tipo da lista (Root) | [] |
| 1b | Processar todos os campos consultados do tipo Root:→ user(by: {id: 1})→ posts(filter: { search: $authorName })Adicionar seus tipos ( User e Post) à lista | [User, Post] |
| 2a | Remover o primeiro tipo da lista (User) | [Post] |
| 2b | Processar o campo consultado do tipo User:→ name @export(as: "authorName")Por ser um tipo escalar ( String), não é necessário adicioná-lo à lista | [Post] |
| 3a | Remover o primeiro tipo da lista (Post) | [] |
| 3b | Processar todos os campos consultados do tipo Post:→ id→ titlePor serem tipos escalares ( ID e String), não é necessário adicioná-los à lista | [] |
| 4 | A lista está vazia, a iteração termina. |
Aqui podemos ver o problema: @export é executado no passo 2b, mas foi lido no passo 1b.
É aqui que precisamos controlar o fluxo de execução dos campos. A solução implementada consiste em atrasar o momento em que a variável exportada é lida, obtido consultando artificialmente o campo self do tipo Root.
O campo self, como o nome indica, retorna o mesmo objeto; aplicado ao objeto Root, retorna o mesmo objeto Root. Você pode se perguntar: "se já tenho o objeto raiz, por que precisaria recuperá-lo novamente?". Porque então o algoritmo do motor precisará adicionar esta nova referência a Root ao final da lista FIFO, e podemos deliberadamente distribuir os campos consultados antes ou depois de cada uma dessas iterações.
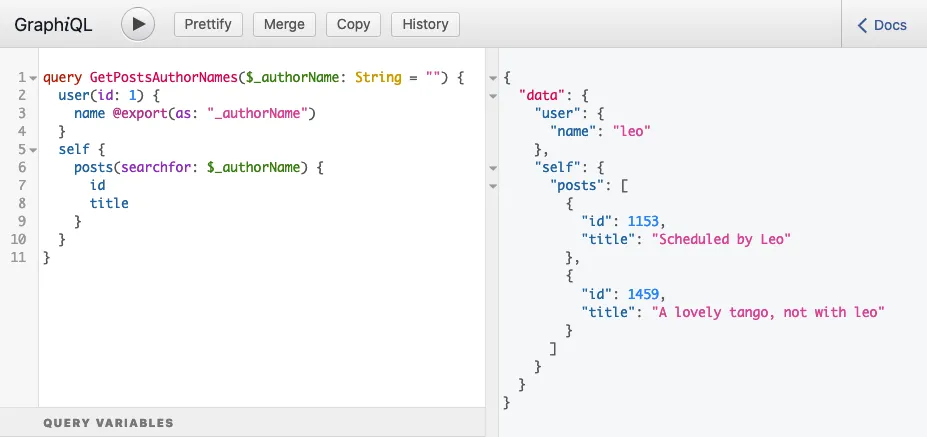
É por isso que o campo posts(filter:{ search: $authorName }) é colocado dentro de um campo self na query acima, e a execução da query produz a resposta esperada:
query GetPostsAuthorNames {
user(by: {id: 1}) {
name @export(as: "authorName")
}
self {
posts(filter: { search: $authorName }) {
id
title
}
}
}
Vamos explorar a ordem em que os tipos são processados para esta query, para entender por que ela funciona corretamente:
| # | Operação | Lista |
|---|---|---|
| 0 | Preparar a lista FIFO | [Root] |
| 1a | Remover o primeiro tipo da lista (Root) | [] |
| 1b | Processar todos os campos consultados do tipo Root:→ user(by: {id: 1})→ selfAdicionar seus tipos ( User e Root) à lista | [User, Root] |
| 2a | Remover o primeiro tipo da lista (User) | [Root] |
| 2b | Processar o campo consultado do tipo User:→ name @export(as: "authorName")Por ser um tipo escalar ( String), não é necessário adicioná-lo à lista | [Root] |
| 3a | Remover o primeiro tipo da lista (Root) | [] |
| 3b | Processar o campo consultado do tipo Root:→ posts(filter:{ search: $authorName })Adicionar seu tipo ( Post) à lista | [Post] |
| 4a | Remover o primeiro tipo da lista (Post) | [] |
| 4b | Processar todos os campos consultados do tipo Post:→ id→ titlePor serem tipos escalares ( ID e String), não é necessário adicioná-los à lista | [] |
| 5 | A lista está vazia, a iteração termina. |
Agora podemos ver que o problema foi resolvido: @export é executado no passo 2b, e é lido no passo 3b.
Multiple Query Execution faz exatamente isso ao desacoplar queries: converte o documento GraphQL adicionando campos self, para que os campos de cada operação sejam executados somente após todos os campos de todas as operações anteriores terem sido resolvidos.