
Motor de carregamento de dados
Gato GraphQL utiliza componentes do lado do servidor para representar o modelo de dados (não grafos nem árvores). Vamos ver como ele executa o processo de carregamento de dados para resolver a query GraphQL.
Para processar os dados, precisamos achatar os componentes em tipos (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor), ordená-los conforme aparecem na hierarquia de componentes (Director, depois Film, depois Actor) e tratá-los em "iterações", recuperando os dados dos objetos de cada tipo em sua própria iteração, assim:

O motor de carregamento de dados do servidor deve implementar o seguinte (pseudo-)algoritmo para carregar os dados:
Preparação:
- Preparar uma fila vazia para armazenar a lista de IDs dos objetos que precisam ser buscados no banco de dados, organizados por tipo (cada entrada será:
[type => lista de IDs]) - Recuperar o ID do objeto do diretor em destaque e colocá-lo na fila sob o tipo
Director
Loop até que não haja mais entradas na fila:
- Obter a primeira entrada da fila: o tipo e a lista de IDs (ex.:
Directore[2]), e remover essa entrada da fila - Usando o objeto
TypeDataLoaderdo tipo, executar uma única query contra o banco de dados para recuperar todos os objetos daquele tipo com esses IDs - Se o tipo possui campos relacionais (ex.: o tipo
Directorpossui o campo relacionalfilmsdo tipoFilm), então coletar todos os IDs desses campos de todos os objetos recuperados na iteração atual (ex.: todos os IDs do campofilmsde todos os objetos do tipoDirector), e colocar esses IDs na fila sob o tipo correspondente (ex.: os IDs[3, 8]sob o tipoFilm).
Ao final das iterações, teremos carregado todos os dados dos objetos para todos os tipos, assim:
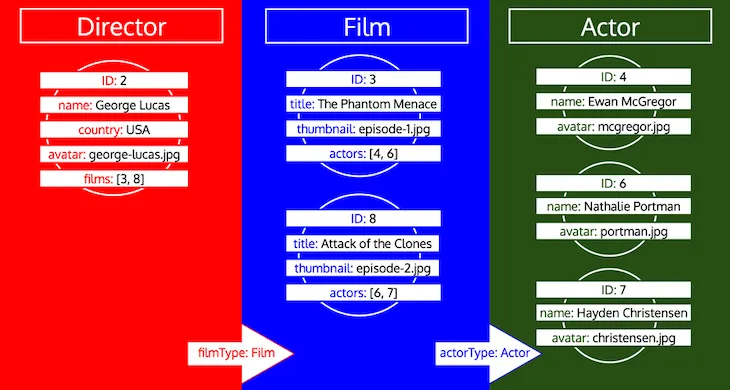
Observe como todos os IDs de um tipo são coletados até que o tipo seja processado na fila. Se, por exemplo, adicionarmos um campo relacional preferredActors ao tipo Director, esses IDs seriam adicionados à fila sob o tipo Actor, e seriam processados junto com os IDs do campo actors do tipo Film:
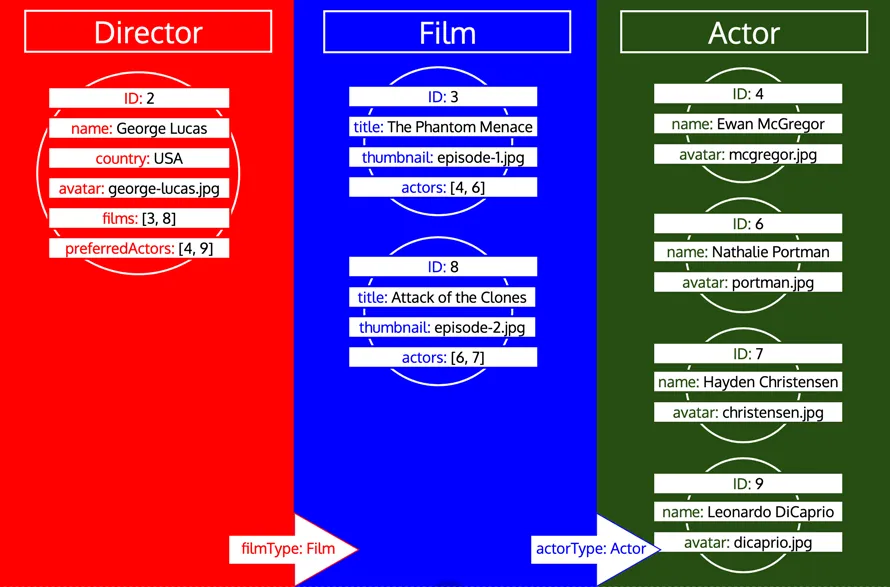
No entanto, se um tipo já foi processado e depois precisamos carregar mais dados daquele tipo, trata-se de uma nova iteração naquele tipo. Por exemplo, adicionar um campo relacional preferredDirector ao tipo Author fará com que o tipo Director seja adicionado à fila novamente:
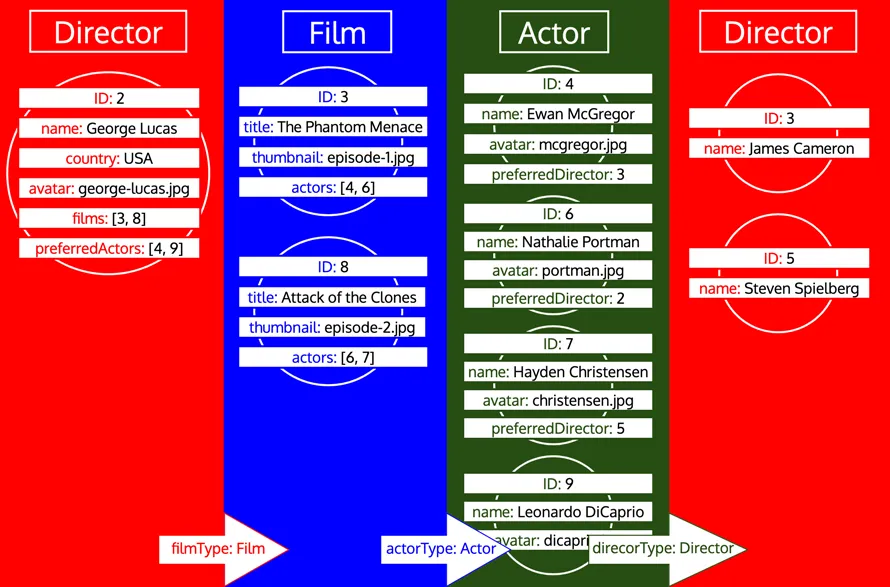
Agora que buscamos todos os dados dos objetos, precisamos moldá-los na resposta esperada, espelhando a query GraphQL. No entanto, como pode ser visto, os dados não têm a estrutura de árvore necessária. Em vez disso, os campos relacionais contêm os IDs do objeto aninhado, emulando como os dados são representados em um banco de dados relacional. Portanto, seguindo essa comparação, os dados recuperados para cada tipo podem ser representados como uma tabela, assim:
Tabela para o tipo Director:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
Tabela para o tipo Film:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
Tabela para o tipo Actor:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
Tendo todos os dados organizados em tabelas, e sabendo como cada tipo se relaciona com os outros (ou seja, Director referencia Film através do campo films, Film referencia Actor através do campo actors), o servidor GraphQL pode facilmente converter os dados na estrutura de árvore esperada:
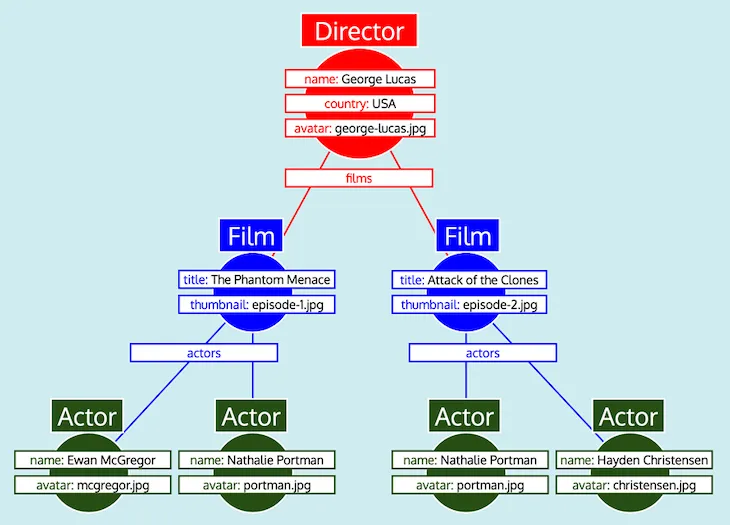
Por fim, o servidor GraphQL emite a árvore, que tem a forma da resposta esperada:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}Analisando a complexidade de tempo da solução
Vamos analisar a notação Big O do algoritmo de carregamento de dados para entender como o número de queries executadas contra o banco de dados cresce à medida que o número de entradas aumenta, para garantir que essa solução seja eficiente.
O motor de carregamento de dados carrega os dados em iterações correspondentes a cada tipo. Quando inicia uma iteração, ele já terá a lista de todos os IDs de todos os objetos a buscar, portanto pode executar uma única query para buscar todos os dados dos objetos correspondentes. Disso decorre que o número de queries ao banco de dados crescerá linearmente com o número de tipos envolvidos na query. Em outras palavras, a complexidade de tempo é O(n), onde n é o número de tipos na query (porém, se um tipo for iterado mais de uma vez, ele deve ser contado mais de uma vez em n).
Essa solução é muito eficiente, muito melhor do que a complexidade exponencial esperada ao lidar com grafos, ou a complexidade logarítmica esperada ao lidar com árvores.
Código PHP implementado
O processo de carregamento de dados ocorre na função getComponentData da classe Engine no pacote Component Model.