
Pipeline de directives
As directives são colocadas em um pipeline e executadas em ordem. Seu design inicial é simples, assim:

Nesta arquitetura:
- A entrada do pipeline é o valor do campo fornecido pelo resolver de campo
- Cada directive executa sua lógica e passa o resultado para a próxima directive no pipeline
- A saída do pipeline será o valor do campo resolvido, após ter sido processado por todas as directives
Esta arquitetura, porém, não aproveita ao máximo o GraphQL. Abaixo está a descrição de todas as etapas do pipeline de directives real, até chegar ao design implementado no Gato GraphQL.
Directives como blocos de construção da resolução da query
Inicialmente poderíamos considerar fazer o servidor GraphQL resolver o campo por meio de algum mecanismo e, em seguida, passar esse valor como entrada para o pipeline de directives.
No entanto, é muito mais simples ter um único mecanismo para lidar com tudo: invocar os resolvers de campo (tanto para validar campos quanto para resolvê-los) já pode ser feito por meio do pipeline de directives. Nesse caso, o pipeline de directives é o único mecanismo usado para resolver a query.
Por esse motivo, o servidor Gato GraphQL é equipado com duas directives especiais:
@validatechama o resolver de campo para validar que o campo pode ser resolvido (ex.: a sintaxe está correta, o campo existe, etc.)- Em caso de sucesso,
@resolveValueAndMergechama o resolver de campo para resolver o campo e mescla o valor no objeto de resposta
Essas duas são do tipo especial de directives "sistema": são reservadas exclusivamente ao motor GraphQL e são implícitas em todo campo. (Em contraste, as directives padrão são explícitas: são adicionadas à query pelo usuário.)
Usando essas duas directives, esta query:
query {
field1
field2 @directiveA
}...será resolvida como esta:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}O pipeline agora se parece com isso (observe que o pipeline recebe o campo como entrada, e não seu valor resolvido inicial):

Slots do pipeline
As directives são normalmente executadas após @resolveValueAndMerge, já que na maioria das vezes envolvem a atualização do valor do campo resolvido. No entanto, existem outras directives que devem ser executadas antes de @validate, ou entre @validate e @resolveValueAndMerge.
Por exemplo:
- Para medir o tempo gasto para resolver um campo, a directive
@traceExecutionTimepode obter o horário atual antes e depois da resolução do campo, colocando as subdirectives@startTracingExecutionTimeno início e@endTracingExecutionTimeno final do pipeline - Uma directive
@cachedeve verificar se um campo solicitado está em cache e retornar essa resposta diretamente, antes de executar@resolveValueAndMerge
O pipeline oferecerá então cinco slots diferentes por meio da classe PipelinePositions, e a directive indicará em qual deles deve ser executada:
- O slot
"beginning": bem no início - O slot
"before-validate": antes que a validação ocorra - O slot
"middle": após a validação e antes da resolução do campo - O slot
"after-resolve": após a resolução do campo - O slot
"end": bem no final
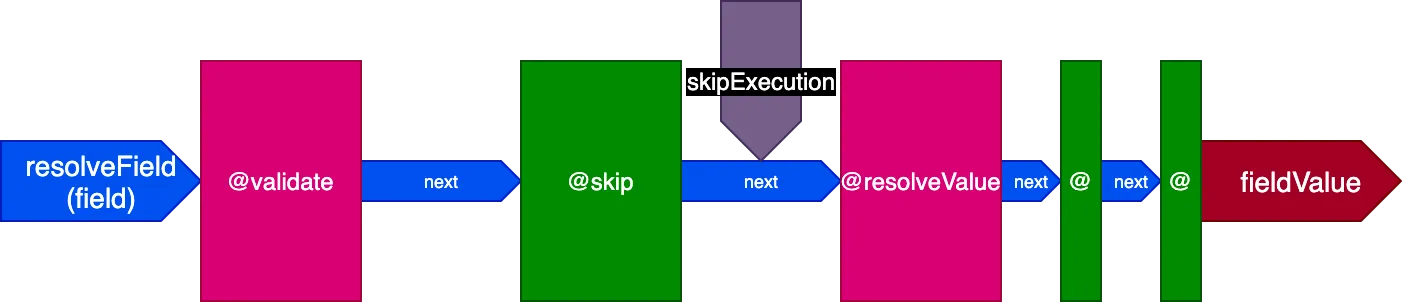
O pipeline de directives agora se parece com isso (considerando apenas 3 etapas, para simplificar):

Observe como as directives @skip e @include podem ser satisfeitas com tanta facilidade nesta arquitetura: colocadas no slot "middle", podem informar a directive @resolveValueAndMerge (juntamente com todas as directives nas etapas posteriores do pipeline) para não executar, definindo o flag skipExecution como true.
Executando a directive em múltiplos campos em uma única chamada
Até agora, consideramos um único campo sendo inserido no pipeline de directives. No entanto, em uma query GraphQL típica, receberemos vários campos nos quais executar directives.
Por exemplo, na query abaixo, a directive @upperCase é executada nos campos "field1" e "field2":
query {
field1 @upperCase
field2 @upperCase
field3
}Além disso, como o motor GraphQL adiciona as directives de sistema @validate e @resolveValueAndMerge a todo campo da query, de modo que esta query:
query {
field1
field2
field3
}...é resolvida como esta query:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Então, as directives de sistema sempre receberão todos os campos como entradas.
Como consequência, o pipeline de directives é projetado para receber múltiplos campos como entrada, e não apenas um de cada vez:

Esta arquitetura é mais eficiente, porque executar uma directive apenas uma vez para todos os campos é mais rápido do que executá-la uma vez por campo, e produzirá os mesmos resultados.
Por exemplo, ao validar se o usuário está logado para conceder acesso ao schema, a operação pode ser executada apenas uma vez. Executar o seguinte código:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}é mais eficiente do que executar este código:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}Isso pode não parecer um grande problema ao chamar uma função local como isUserLoggedIn, porém pode fazer uma grande diferença ao interagir com serviços externos, como ao resolver endpoints REST por meio do GraphQL. Nesses casos, executar uma função uma vez em vez de múltiplas vezes pode fazer a diferença entre ser capaz de fornecer uma determinada funcionalidade ou não.
Vejamos um exemplo. Ao interagir com o Google Translate por meio de uma directive @translate, a API GraphQL deve estabelecer uma conexão pela rede. Então, executar este código será tão rápido quanto possível:
googleTranslateFields([$field1, $field2, $field3]);Em contraste, executar a função separadamente, múltiplas vezes, produzirá uma latência maior que resultará em um tempo de resposta mais alto, degradando o desempenho da API. Possivelmente isso não é uma grande diferença para traduzir 3 strings (onde o campo é a string a ser traduzida), mas para 100 ou mais strings certamente terá impacto:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);Além disso, executar uma função uma vez com todas as entradas pode produzir uma resposta melhor do que executar a função em cada campo independentemente. Usando o Google Translate novamente como exemplo, a tradução será mais precisa quanto mais dados fornecermos ao serviço.
Por exemplo, ao executar o código abaixo:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");Na primeira execução independente, o Google não conhece o contexto de "fork", então pode muito bem responder com fork como utensílio para comer, como uma bifurcação de estrada, ou com outro significado. No entanto, se executarmos em vez disso:
googleTranslate(["fork", "road", "sign"]);Com essa quantidade maior de informações, o Google pode deduzir que "fork" se refere à bifurcação da estrada e retornar uma tradução precisa.
É por essas razões que as directives no pipeline recebem os campos de entrada todos juntos, e então cada directive pode decidir a melhor maneira de executar sua lógica sobre essas entradas (uma única execução por entrada, uma única execução abrangendo todas as entradas, ou qualquer coisa entre os dois extremos).
O pipeline agora se parece com isso:
Executando um único pipeline de directives para toda a query
Acabamos de aprender que faz sentido executar múltiplos campos por directive, porém isso funciona bem enquanto todos os campos têm as mesmas directives aplicadas a eles. Quando as directives são diferentes, isso pode levar a uma maior complexidade que torna sua implementação difícil, e reduziria alguns dos benefícios obtidos.
Vejamos como isso acontece. Considere a seguinte query:
query {
field1 @directiveA
field2
field3
}Esta directive é equivalente a esta:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Nesse cenário, os campos field2 e field3 têm o mesmo conjunto de directives, e field1 tem um conjunto diferente, então teríamos que gerar 2 pipelines diferentes para resolver a query:
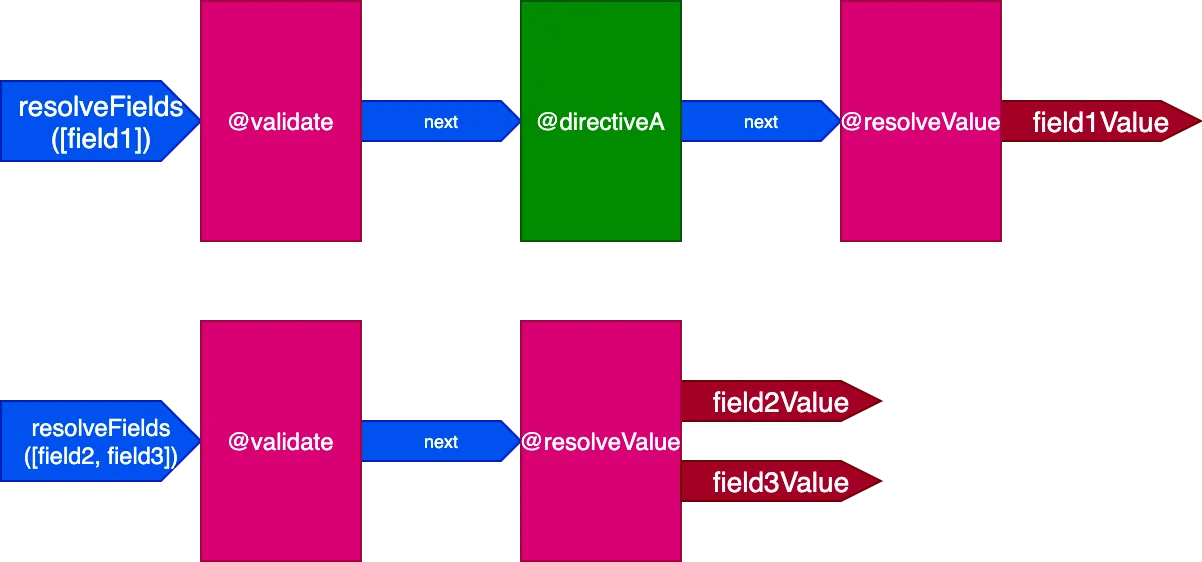
E quando todos os campos têm um conjunto único de directives, o efeito é ainda mais pronunciado. Considere esta query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}Que é equivalente a esta:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}Nessa situação, teremos 3 pipelines para lidar com 3 campos, assim:
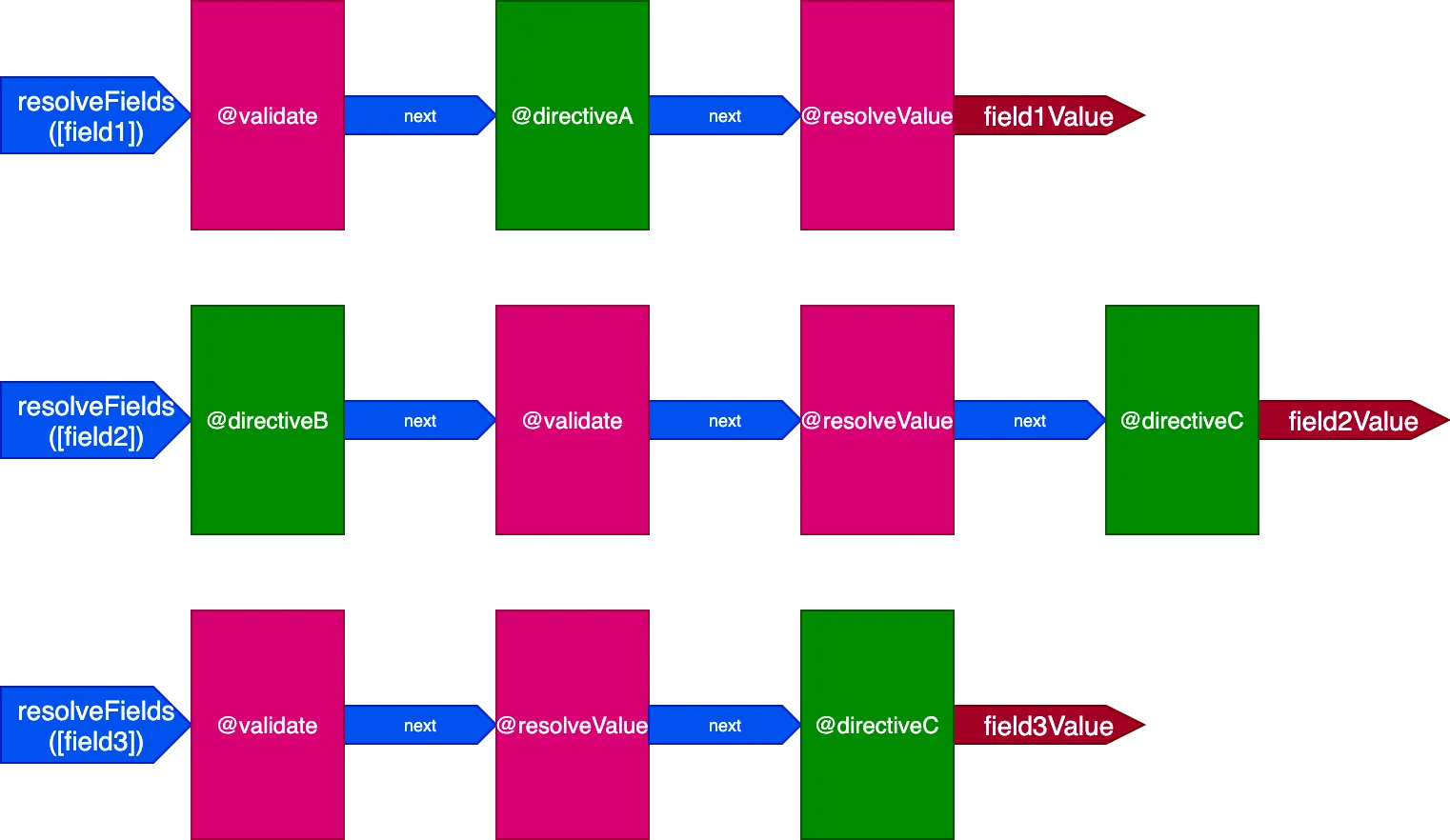
Nesse caso, mesmo que as directives @validate e @resolveValueAndMerge sejam aplicadas nos 3 campos, como são executadas por meio de 3 pipelines de directives diferentes, elas serão executadas independentemente umas das outras, o que nos leva de volta a ter uma directive executada em um único item de cada vez.
A solução para esse problema é evitar produzir múltiplos pipelines, mas trabalhar com um único pipeline para todos os campos. Como consequência, o motor não passa mais os campos como entrada para o pipeline, já que nem todas as directives de um único pipeline interagirão com o mesmo conjunto de campos; em vez disso, cada directive deve receber sua própria lista de campos como sua própria entrada.
Então, para esta query:
query {
field1 @directiveA
field2
field3
}...as directives @validate e @resolveValueAndMerge receberão todos os 3 campos como entradas, e directiveA receberá apenas "field1":
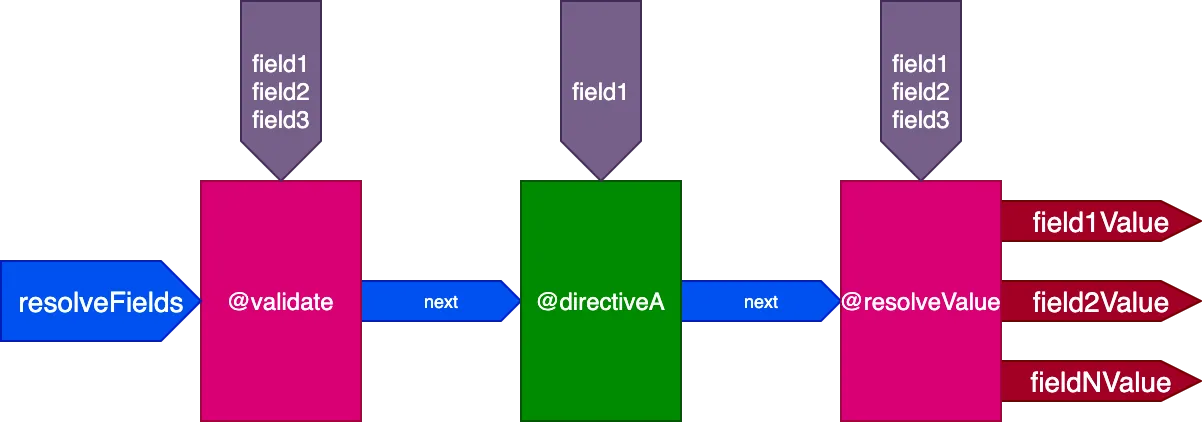
E para esta query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...as directives @validate e @resolveValueAndMerge receberão todos os 3 campos como entradas, directiveA receberá apenas "field1", directiveB receberá apenas "field2", e directiveC receberá "field2" e "field3":
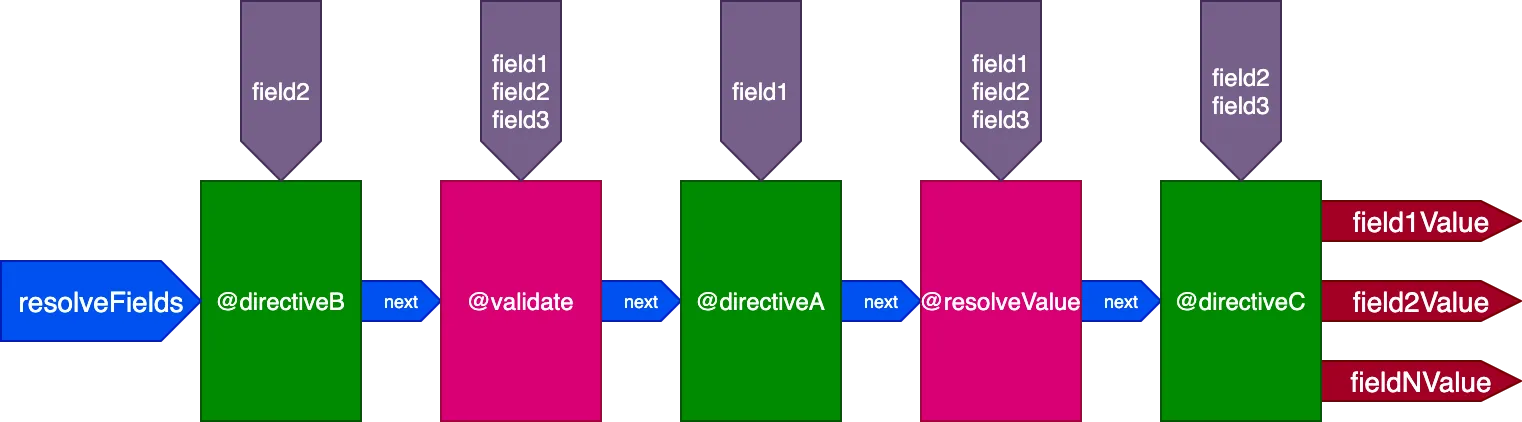
Controlando a execução da directive ID por ID
Até agora, uma directive em alguma etapa podia influenciar a execução de directives em etapas posteriores por meio de um flag skipExecution. No entanto, esse flag não é granular o suficiente para todos os casos.
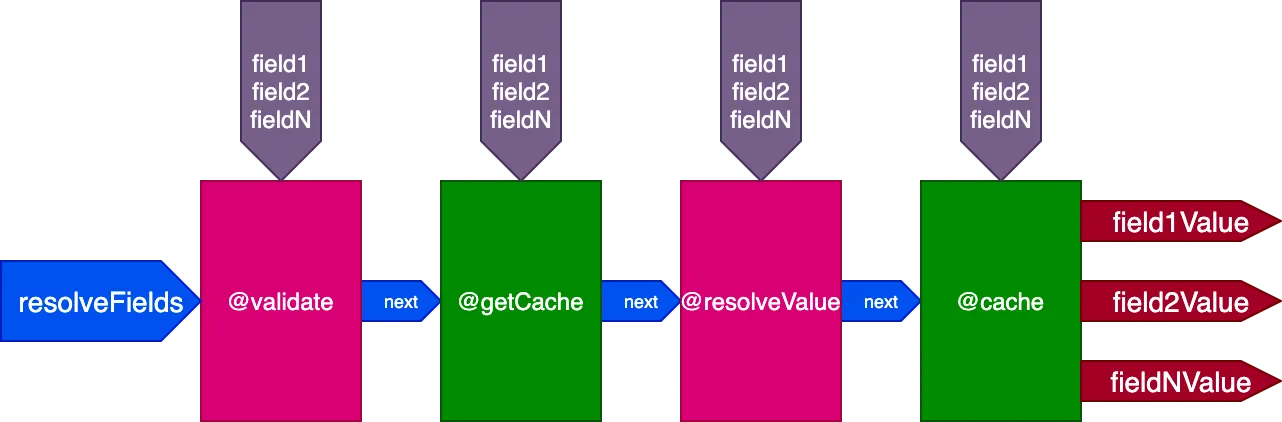
Por exemplo, considere uma directive @cache, colocada no slot "end" para armazenar o valor do campo, de modo que na próxima vez que o campo for consultado, seu valor possa ser recuperado do cache por meio de uma directive @getCache colocada no slot "middle":
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}O servidor recuperará e armazenará em cache 2 registros. Em seguida, executamos a mesma query, mas aplicada a 4 registros:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}Ao executar esta 2ª query, os 2 registros da 1ª query já estavam em cache, mas os outros 2 registros não estavam. No entanto, precisaríamos que todos os 4 registros já estivessem em cache para usar o flag skipExecution. Seria melhor se pudéssemos recuperar os primeiros 2 registros do cache e resolver apenas os outros 2 registros.
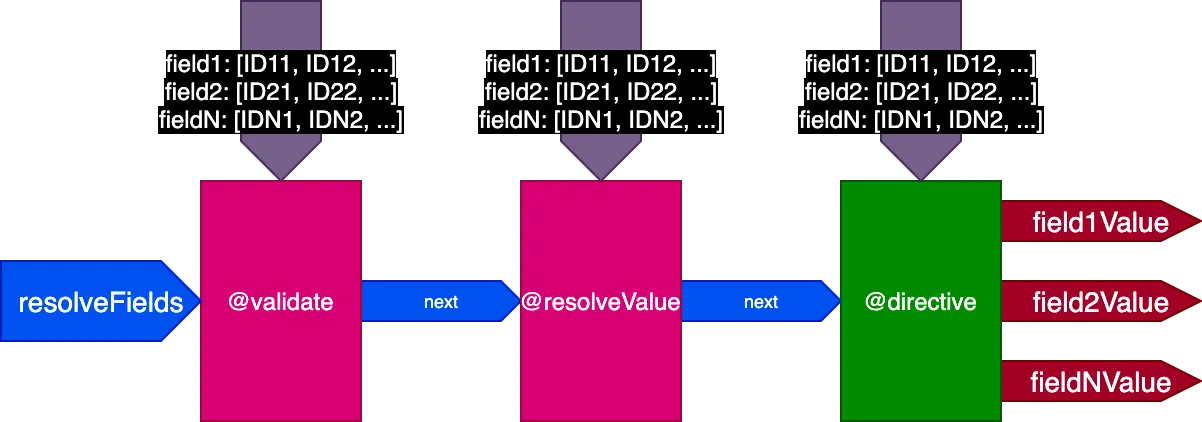
Então atualizamos o design do pipeline novamente. Eliminamos o flag skipExecution e, em vez disso, passamos para cada directive a lista de IDs de objetos por campo onde a directive deve ser aplicada, por meio de um objeto de entrada fieldIDs:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}A variável fieldIDs é única para cada directive, e cada directive pode modificar a instância de fieldIDs para todas as directives em etapas posteriores. Então, skipExecution pode ser feito de forma granular, ID por ID, simplesmente removendo o ID de fieldIDs para todas as directives subsequentes na pilha.
O pipeline agora se parece com isso:
Aplicado ao exemplo anterior, ao executar a primeira query traduzindo 2 registros, o pipeline se parece com isso:
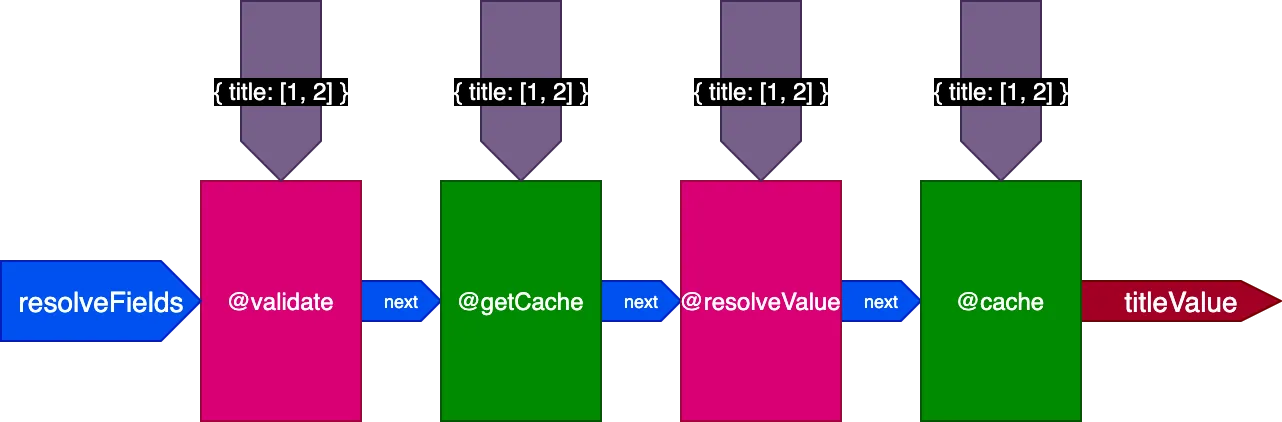
Ao executar a segunda query traduzindo 4 registros, a directive @getCache recebe os IDs de todos os 4 registros, mas tanto @resolveValueAndMerge quanto @cache receberão apenas os IDs dos últimos 2 registros (que não estão em cache):
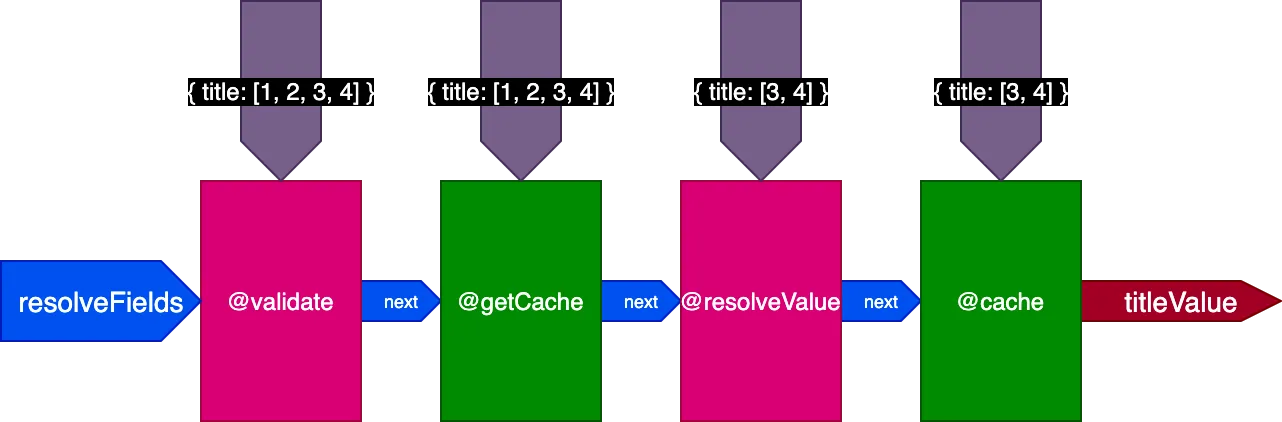
Unindo tudo
Este é o design final do pipeline de directives:
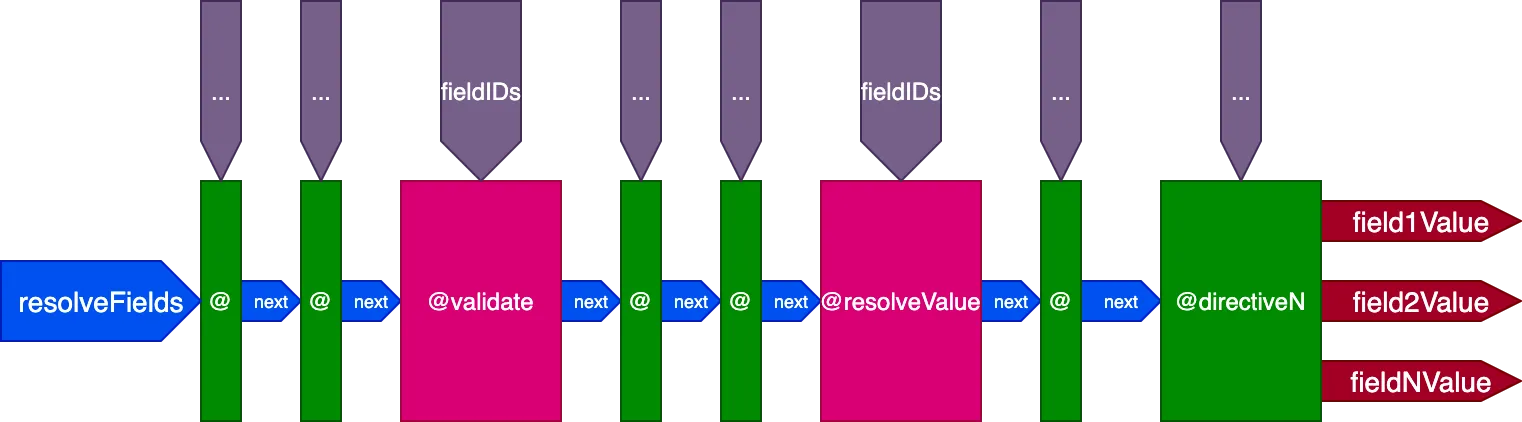
Em resumo, estas são suas características:
- Os resolvers de campo são invocados de dentro do próprio pipeline de directives, por meio das directives
@validatee@resolveValueAndMerge - As directives podem ser colocadas em qualquer um dos 5 slots:
"beginning","before-validate","middle","after-validate"e"end" - As directives resolvem múltiplos campos em uma única chamada
- Um único pipeline contém todas as directives envolvidas na query
- Cada directive recebe seu próprio conjunto de IDs a resolver por campo por meio da variável
fieldIDs - As directives podem modificar a variável
fieldIDspara todas as directives em uma etapa posterior do pipeline